Github 에서 해당 내용에 대해서 확인할 수 있습니다.
Overview
목표
- mlflow에 저장된 모델을 다운로드 받을 수 있는 스크립트를 작성합니다.
요구사항
- run id를 입력하면 mlflow에 저장된 모델을 다운로드 받을 수 있는 스크립트를 작성합니다.
- python sdk:
mlflow.MlflowClient - bash:
rclone
- 앞선 챕터에서 로깅된 run_id를 이용해 모델을 다운로드 합니다.
- 다운로드 받은 모델을
mlflow.pyfunc.load_model 을 이용해 load 합니다.
Download Model
Run List
mlfow에 저장되어 있는 run list를 확인합니다.
1
2
3
4
5
6
| import mlflow
client = mlflow.MlflowClient("http://localhost:5000")
runs = client.list_run_infos(experiment_id=0)
run_ids = [run.run_id for run in runs]
|
해당 스크립트를 실행하면 run_ids 에 다음과 같이 저장되어 있습니다.
1
2
| >>> run_ids
["1e3a1e8a345d4365a971dded8693938b"]
|
이 run_id는 mlflow web 에서 표시되는 것 과 동일한 것을 확인할 수 있습니다.
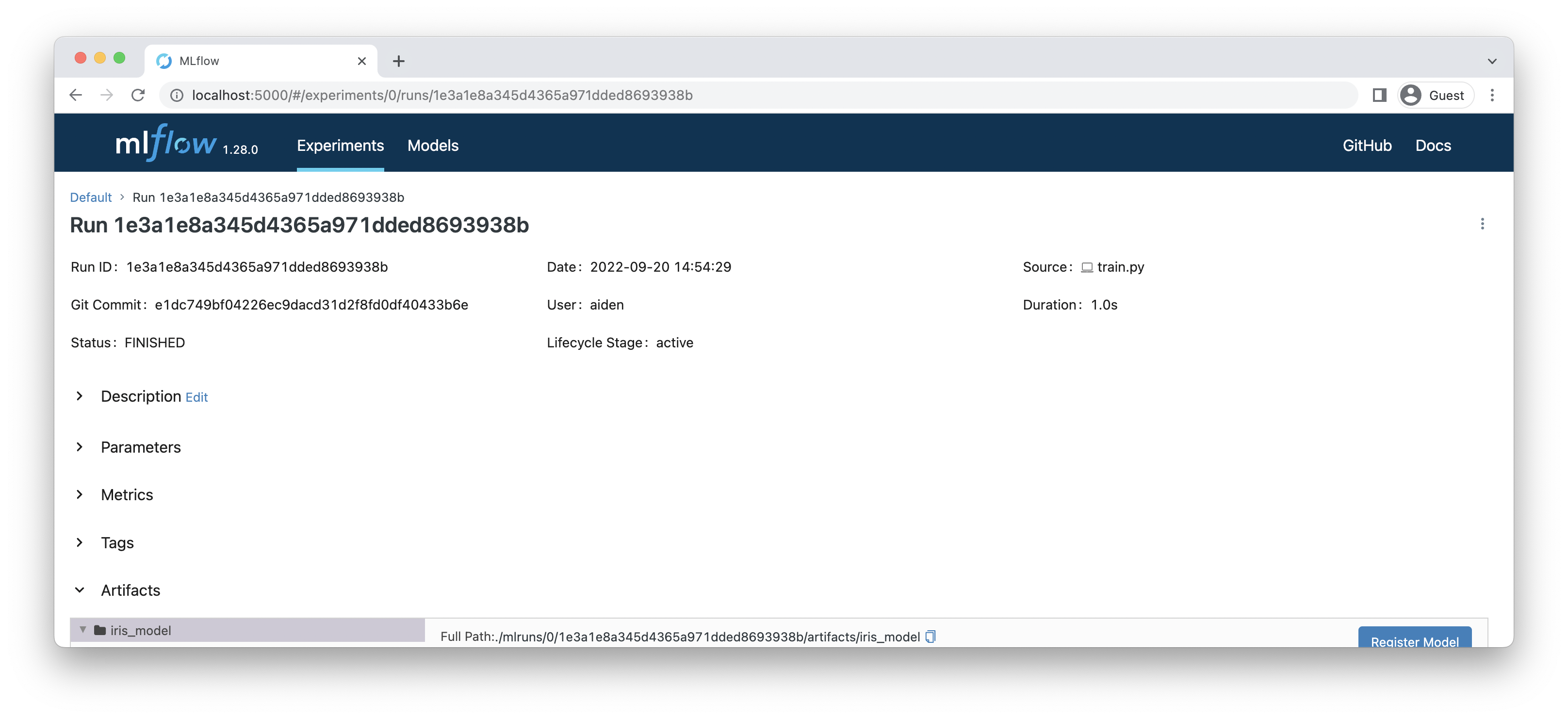
Download Artifact
다음으로 run_id 의 모델을 다운로드 받을 수 있는 코드를 작성합니다. 이 때 주의해야 할 점은 run_id의 정보로 얻을 수 있는 artifact_path는 전체 artifact 들의 root 주소입니다. 그래서 필요한 모델만을 받기 위해서 list_artifacts로 전체 파일 및 폴더 목록을 확인하고 모델이 저장되어 있는 폴더만을 다운로드 받도록 합니다.
1
2
3
4
5
6
7
8
9
| import os
import mlflow
os.makedirs("download", exist_ok=True)
run_id = "1e3a1e8a345d4365a971dded8693938b"
client = mlflow.MlflowClient("http://localhost:5000")
artifact = client.list_artifacts(run_id)[0].path
client.download_artifacts(run_id=run_id, path=artifact, dst_path=download)
|
위 코드를 실행시키면 아래와 같이 download 폴더 밑에 iris_model 이 있음을 확인할 수 있습니다.
1
2
3
4
5
6
7
8
| .
├── download
│ └── iris_model
│ ├── MLmodel
│ ├── conda.yaml
│ ├── model.pkl
│ ├── python_env.yaml
│ └── requirements.txt
|
Load Model
이제 다운로드 받은 모델을 load 하는 코드를 작성합니다.
1
2
3
4
| import mlflow
dst_path = "download/iris_model"
model = mlflow.pyfunc.load_model(dst_path)
|
load된 모델을 확인하면 다음과 같습니다.
1
2
3
4
5
6
| >>> model
mlflow.pyfunc.load_model("download/iris_model")
mlflow.pyfunc.loaded_model:
artifact_path: iris_model
flavor: mlflow.sklearn
run_id: 1e3a1e8a345d4365a971dded8693938b
|
load된 모델이 iris 데이터를 predict 할 수 있는지 확인합니다.
1
2
3
4
5
6
7
8
9
10
11
12
| from sklearn.datasets import load_iris
df, _ = load_iris(return_X_y=True, as_frame=True)
rename_rule = {
"sepal length (cm)": "sepal_width",
"sepal width (cm)": "sepal_length",
"petal length (cm)": "petal_width",
"petal width (cm)": "petal_length",
}
df = df.rename(columns=rename_rule)
sample = df.sample(1)
pred = model.predict(sample)
|
데이터와 예측값을 확인하면 다음과 같습니다.
1
2
3
4
5
6
| >>> sample
sepal_width sepal_length petal_width petal_length
2 4.7 3.2 1.3 0.2
>>> pred
[0]
|
이렇게 load된 모델이 정상적으로 predict 할 수 있음을 확인했습니다.