CKA를 준비하면서 공부한 요약 내용입니다.
Operating System Upgrade
- upgrading base software
- applying security patches
Pod Eviction Timeout
- waiting pod healthy
pod-eviction-timeout=5m0s
Drain
Do not use this node, and all pods are out.
kubectl drain node01kubectl drain node01 --ignore-daemonsets1 2 3 4 5 6 7 8 9 10root@controlplane:~# kubectl drain node01 --ignore-daemonsets node/node01 cordoned WARNING: ignoring DaemonSet-managed Pods: kube-system/kube-flannel-ds-x6dgs, kube-system/kube-proxy-jfmxw evicting pod default/blue-746c87566d-wn2qg evicting pod default/blue-746c87566d-kt266 evicting pod default/blue-746c87566d-9w9zq pod/blue-746c87566d-kt266 evicted pod/blue-746c87566d-wn2qg evicted pod/blue-746c87566d-9w9zq evicted node/node01 evictedkubectl drain node01 --ignore-daemonsets --force
if a pod in node has no replicaset, use--forceoption, but a pod will be lost.1 2 3 4 5 6root@controlplane:~# kubectl drain node01 --ignore-daemonsets --force node/node01 already cordoned WARNING: deleting Pods not managed by ReplicationController, ReplicaSet, Job, DaemonSet or StatefulSet: default/hr-app; ignoring DaemonSet-managed Pods: kube-system/kube-flannel-ds-x6dgs, kube-system/kube-proxy-jfmxw evicting pod default/hr-app pod/hr-app evicted node/node01 evicted
Cordon
Do not use this node, but exist pods will be running.
kubectl cordon node01- This will ensure that no new pods are scheduled on this node.
- The existing pods will not be affected by this operation.
Uncordon
Can use this node.
kubectl uncordon node01
Cluster Upgrade Process
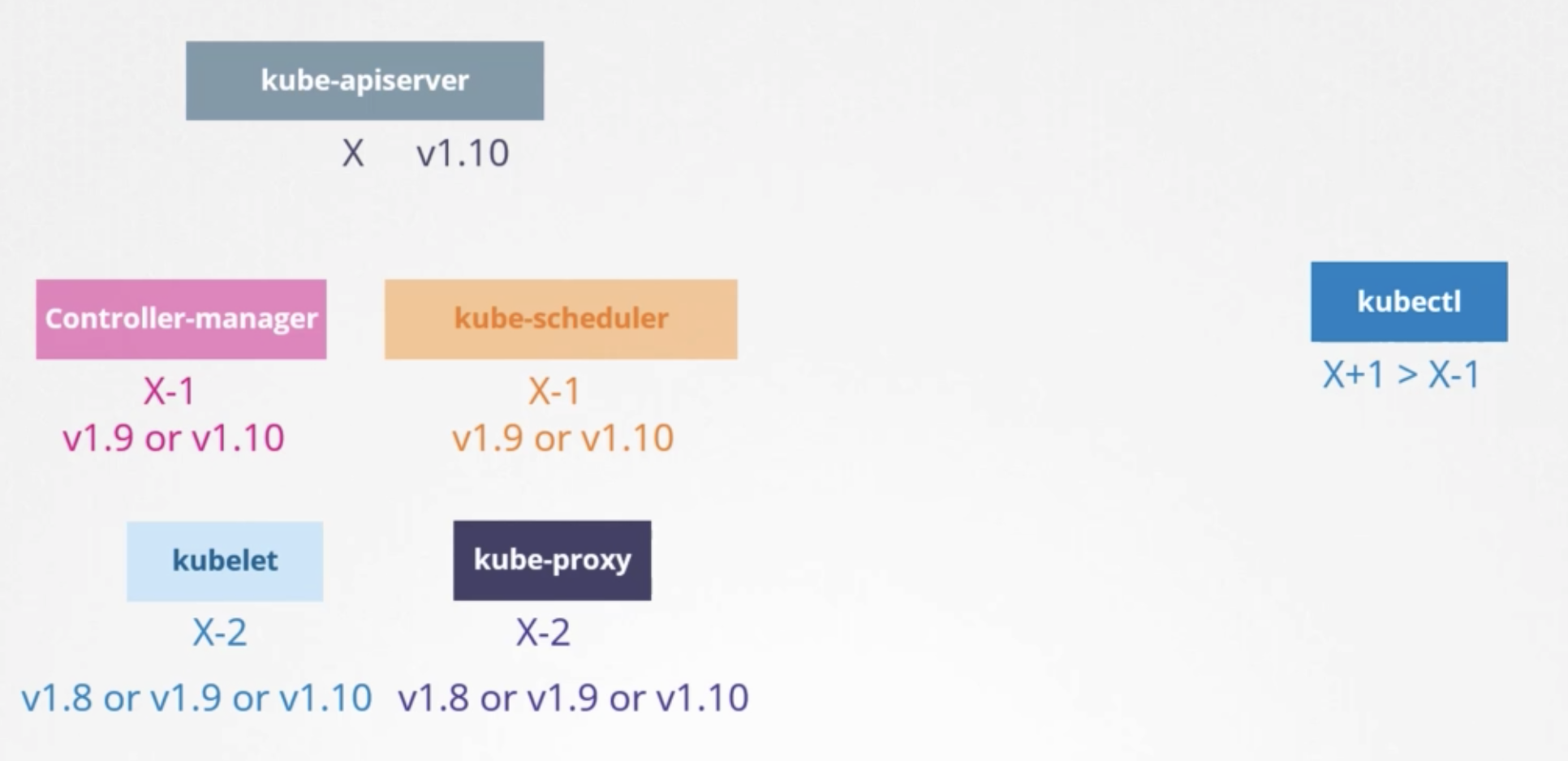
Supported versions
gcp
kubeadm
kubectl upgrade plan1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46root@controlplane:~## kubeadm upgrade plan [upgrade/config] Making sure the configuration is correct: [upgrade/config] Reading configuration from the cluster... [upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [preflight] Running pre-flight checks. [upgrade] Running cluster health checks [upgrade] Fetching available versions to upgrade to [upgrade/versions] Cluster version: v1.19.0 [upgrade/versions] kubeadm version: v1.19.0 I0522 08:54:38.911002 21647 version.go:252] remote version is much newer: v1.21.1; falling back to: stable-1.19 [upgrade/versions] Latest stable version: v1.19.11 [upgrade/versions] Latest stable version: v1.19.11 [upgrade/versions] Latest version in the v1.19 series: v1.19.11 [upgrade/versions] Latest version in the v1.19 series: v1.19.11 Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply': COMPONENT CURRENT AVAILABLE kubelet 2 x v1.19.0 v1.19.11 Upgrade to the latest version in the v1.19 series: COMPONENT CURRENT AVAILABLE kube-apiserver v1.19.0 v1.19.11 kube-controller-manager v1.19.0 v1.19.11 kube-scheduler v1.19.0 v1.19.11 kube-proxy v1.19.0 v1.19.11 CoreDNS 1.7.0 1.7.0 etcd 3.4.9-1 3.4.9-1 You can now apply the upgrade by executing the following command: kubeadm upgrade apply v1.19.11 Note: Before you can perform this upgrade, you have to update kubeadm to v1.19.11. _____________________________________________________________________ The table below shows the current state of component configs as understood by this version of kubeadm. Configs that have a "yes" mark in the "MANUAL UPGRADE REQUIRED" column require manual config upgrade or resetting to kubeadm defaults before a successful upgrade can be performed. The version to manually upgrade to is denoted in the "PREFERRED VERSION" column. API GROUP CURRENT VERSION PREFERRED VERSION MANUAL UPGRADE REQUIRED kubeproxy.config.k8s.io v1alpha1 v1alpha1 no kubelet.config.k8s.io v1beta1 v1beta1 no _____________________________________________________________________kubectl upgrade apply
Kubeadm
Strategy
- strategy-1
- all node down and up
- strategy-2
- upgrade node one by one
- strategy-3
- add new version node and remove old node
- easy in cluster
Procedure
- master node
- ver 1
apt-get upgrade -y kuebadm=1.12.0-00kubeadm upgrade apply v1.12.0apt-get upgrade -y kubelet=1.12.0-00systemctl restart kubelet
- ver 2
apt updateapt install kubeadm=1.20.0-00kubeadm upgrade apply v1.20.0apt install kubelet=1.20.0-00systemctl restart kubelet
- ver 1
- worker node
- ver 1
kubectl drain node01apt-get upgrade -y kuebadm=1.12.0-00apt-get upgrade -y kubelet=1.12.0-00kubeadm upgrade node config --kubelet-version v1.12.0systemctl restart kubeletkubectl uncordon node01
- ver 2
apt updateapt install kubeadm=1.20.0-00kubeadm upgrade nodeapt install kubelet=1.20.0-00systemctl restart kubelet
- ver 1
Backup and Restore
Backup Candidates
- Resource Configuration
- ETCD Cluster
- Persistent Volumes
Resource Configuration
- kube-apiserver
kubectl get all -A -o yaml > all-deploy-svc.yaml- too many resource to do
- → opensource like VELERO
ETCD
method 1
ExecStart= ... \\ --data-dir=/var/lib/etct
method 2
ETCDCTL_API=3 etcdctl snapshot save snapshot.dbservcie kube-apiserver stopETCDCTL_API=3 etcdctl snapshot --data-dir /var/lib/etcd-from-backup snapshot restore snapshot.dbsystemctl daemon-reloadservice etcd restartservice kube-apiserver start
backup practice
1 2 3 4 5ETCDCTL_API=3 etcdctl --endpoints=https://[127.0.0.1]:2379 \\ --cacert=/etc/kubernetes/pki/etcd/ca.crt \\ --cert=/etc/kubernetes/pki/etcd/server.crt \\ --key=/etc/kubernetes/pki/etcd/server.key \\ snapshot save /opt/snapshot-pre-boot.dbrestore practice
- Restore snapshot
1 2ETCDCTL_API=3 etcdctl --data-dir /var/lib/etcd-from-backup \\ snapshot restore /opt/snapshot-pre-boot.db - update the
/etc/kubernetes/manifests/etcd.yaml1 2 3 4 5volumes: - hostPath: path: /var/lib/etcd-from-backup type: DirectoryOrCreate name: etcd-data
- Restore snapshot