![Featured image of post [ Chapter 2. Model Registry ] 3) Train Model and Save to MLFlow](/post/mle-mlops/model_registry/train_save_model/run_hu8d915c21553f04f6ea76560c746482be_1308795_800x0_resize_box_3.png)
Github 에서 해당 내용에 대해서 확인할 수 있습니다.
Overview
목표
- 모델을 학습하고 mlflow server에 저장합니다.
요구사항
앞선 챕터에서 추출한 데이터를 이용해 모델을 학습합니다.
- eg)
from sklearn.svm import SVC - 모델을 학습하는 스크립트의 위치는 mlflow server 가 띄어진 위치와 같아야 합니다.
1 2 3 4 5. ├── mlruns │ └── 0 │ └── meta.yaml └── train.py
- eg)
학습이 끝난 모델을 built-in method를 사용해 mlflow server에 저장합니다.
- Python의
mlflow패키지를 이용합니다.pip install mlflow
- mlflow를 이용해 logging 하는 방법은 두 가지가 있습니다.
- fluent
- client [MLFlow Client]
- mlflow에는 모델을 저장하는 방법은 두 가지가 있습니다.
- artifact 처럼 다루기 [MLFLow log_artifact]
- built-in method 사용하기
- Python의
저장된 모델을 mlflow website에서 확인합니다.
- 모델이 어떻게 저장되어 있는지 확인합니다. [MLFlow Storage Format]
Train
모델을 학습하는 스크립트를 작성합니다. 이 때 데이터는 이 전 챕터에서 사용한 데이터를 이용합니다.
| |
Save Model
mlflow를 사용할 수 있는 방법중 fluent 와 built-in method를 사용해 모델을 저장하겠습니다.
Set Tracking URI
우선 앞선 챕터에서 띄운 mlflow server에 로깅할 수 있도록 set_tracking_uri를 이용해 mlflow 의 주소를 지정합니다.
| |
Log Model
다음으로 built-in method 중 학습한 모델이 scikit-learn 모델이기 때문에 mlflow.sklearn 를 이용해 모델을 저장합니다.
| |
위 명령어를 실행하면 다음과 같이 mlruns에 run_id 폴더가 생성되고 밑에 필요한 정보들이 추가됩니다.
| |
Web
http://localhost:5000 에 접속하면 다음과 같이 나옵니다.
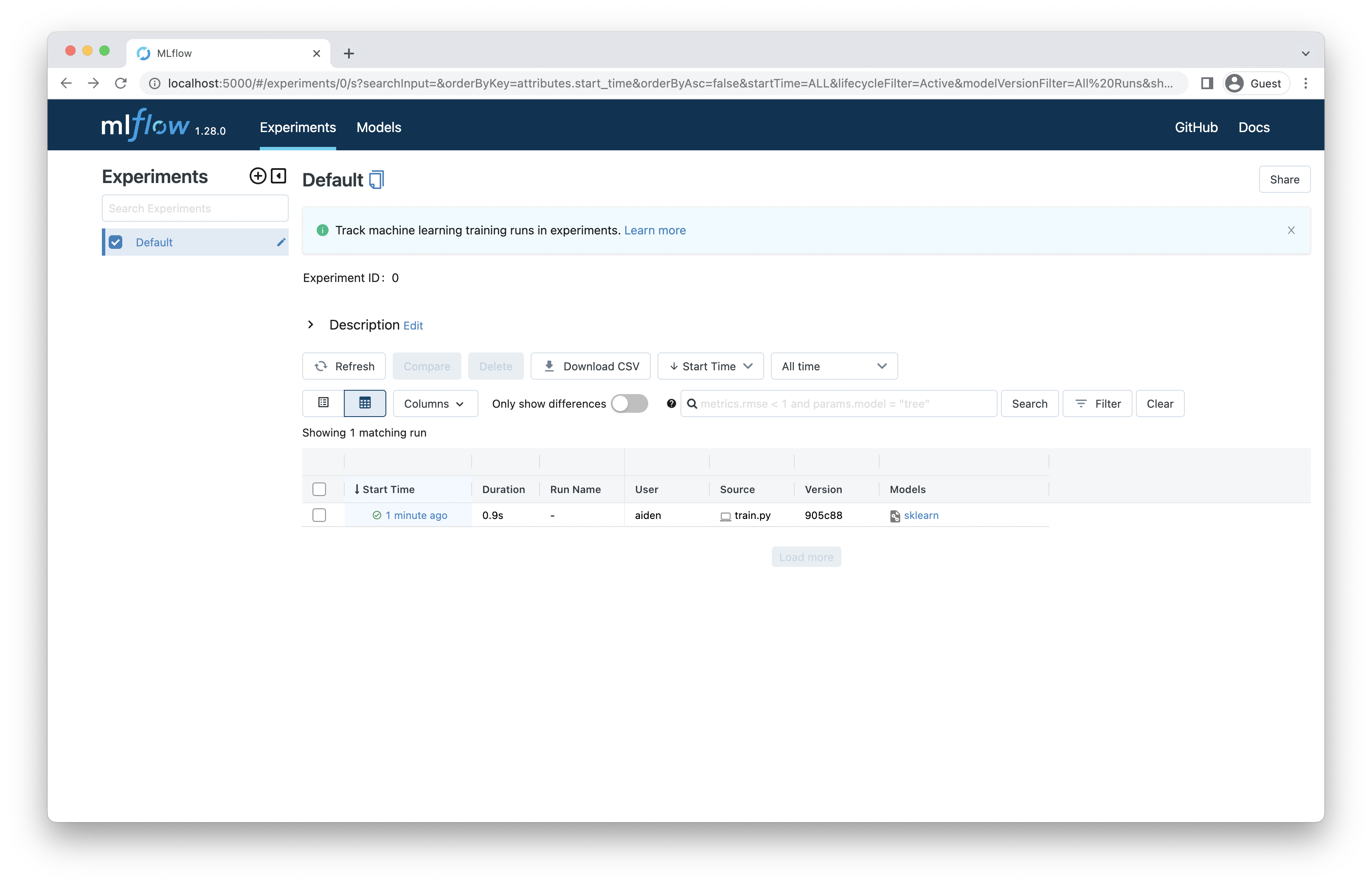
생성된 run을 클릭합니다.
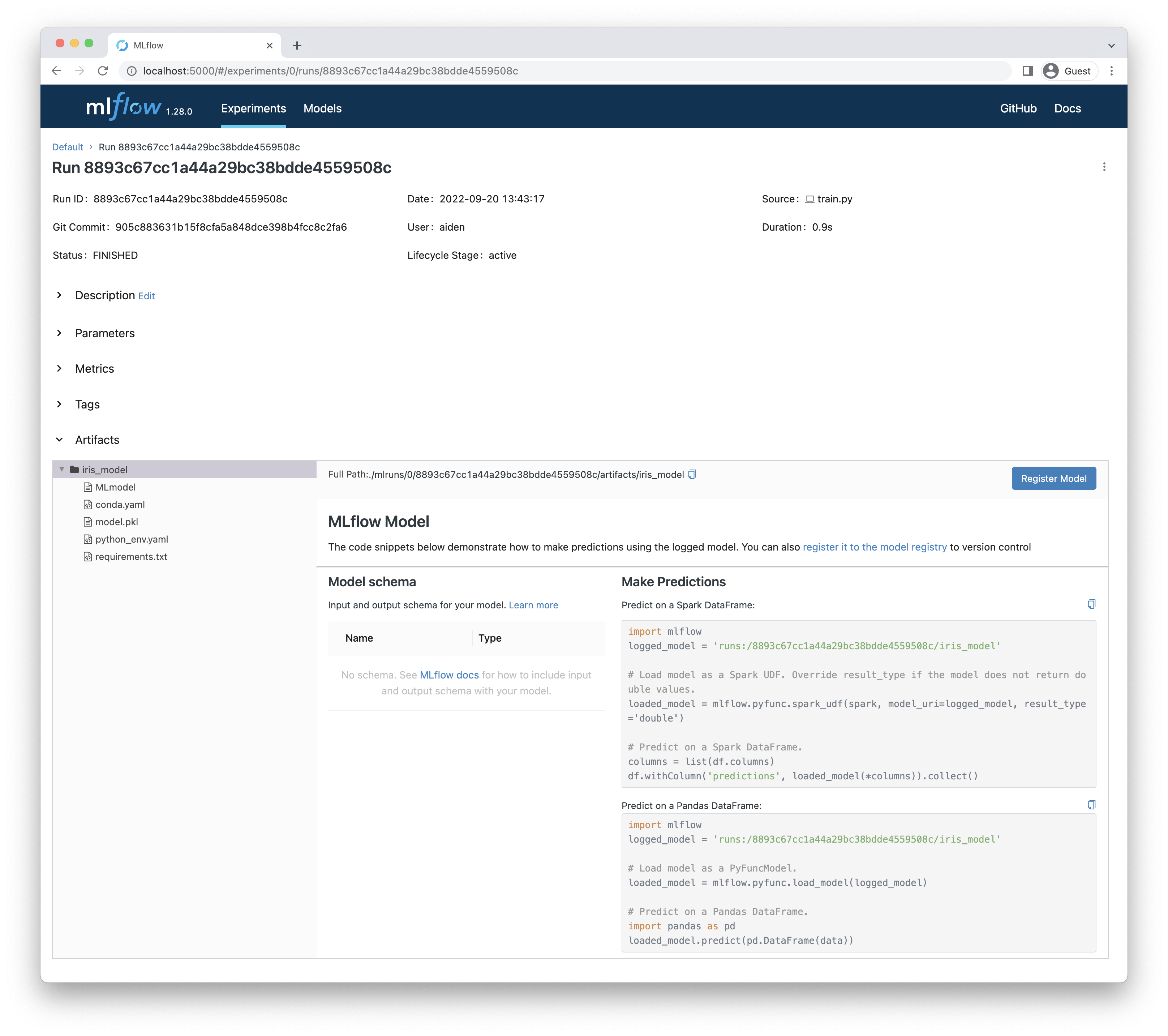
위와 같이 artifacts에 iris_model 폴더 밑에 모델과 메타 정보들이 저장된 것을 확인할 수 있습니다.