Apache Kafka 101
1. Events
Kafka
- many use cases
- ⇒ start from event streaming platform
Event
- What is Event?
- things that have happened combined with the description of what happend
- ⇒ notification + state
- eg)
- IOT
- Business Process Change
- User Interaction
- Microservice Output
- Notification
- the element of when-ness that can be used to trigger some other activity
- State
- Usually small (less than a megabyte)
- normally represented in some structured format (JSON, an object serialized with Apache Avro or Protocol Buffers)
Key / Value
- kafka models events as key/value pair
- Internally: sequence of bytes
- externally: structured objects represented in language’s type system
- (JSON, JSON Schema, Avro, or Protobuf)
3. Topics
Topic
- most fundamental unit of Kafka
- something like a table in a relational database
Named container for similar events
- create different topics to hold
- different kinds of events
- filtered and transformed versions of the same kind of event
- → can duplicate data between topics
A topic is a log of events
- Logs
- Append only: when writing a new message into a log, it always goes on the end
- Can only seek by offset, not indexed
- Immutable: once something has happened, it is difficult to make it un-happen
Topics are durable
- Logs are durable
- Retention is configurable
- expire data after it has reached a certain age
- topic overall reached a certain size
- Logs on Kafka topics are files stored on disk
- write on event to a topic, it is durable as it would be of you had written it to any database you ever trusted.
4. Partitioning
- Kafka: Distributed System
- no one topic could ever get too big
- aspire to accommodate too many reads and writes
What is Partitioning?
- takes the single topic log
- → breaks it into multiple logs
- → each of which can live on a separate node on cluster
- need a way of deciding which messages to write to which partition
- message with no key
- message with a key
Message with no key
- round-robin among all the topic’s partitions
- pros) all partitions get an even share of the data
- cons) don’t preserve any kind of ordering of the input message
Message with a key
- destination partition will be computed from a has of the key
- output of hash function mode of # of partitions
- guarantee that messages having same key always land in same partition
- pros) always in order
- cons) what if very active key? → a larger and more active partition
- ⇒ risk is small in practice and manageable
6. Brokers
Kafka Brokers
- Actual Computers
- Kafka is composed of a network of machines called brokers
- machines can be an computer, instance, or container running the Kafka process
- Each broker hosts some set of Kafka partitions
- handles incoming requests
- to write new events to those partitions
- to read events from them
- handles replication of partitions
- handles incoming requests
7. Replication
- Copies of data for fault tolerance
- if we store each partition to one broker → susceptible to failure → we need copy partitions data to several brokers
- One lead partition and N-1 followers
- Leader: writes and reads happens
- Follower: works together to replicate those new writes
- Automatic process → developer don’t need to worry about it
8. Producers
Kafka Producer
- application using Kafka : Producer and Consumer
- Producing and Consuming: how to interface with cluster
- API surface of the producer library is fairly lightweight
9. Consumers
Kafka Consumer
- many consumers read one topic
- reading does not destroy message
- Rebalancing processes
- using same group ID → fairly split data to consumer
- traditional topic
- keep ordering guarantee in place
- sacrifice the ability to scale out consumers
11. Ecosystem
- Infrastructure
- doesn’t contribute value directly to customers
- best case ← provided by community or an infrastructure vendor
- eg)
- Kafka Connect
- Confluent Schema Registry
- Kafka Streams
- ksqlDB
12. Kafka Connect
- Job of Kafka connect
- the data those other systems to get into Kafka topics
- data in Kafka topics to get into those system
What does Kafka Connect Do?
- Data integration system and ecosystem
- a client application
- External client process; does not run on Brokers
- if something is not a broker is an producer or and consumer
- Horizontally scalable
- Fault-tolerant
- External client process; does not run on Brokers
How Kafka Connect Works
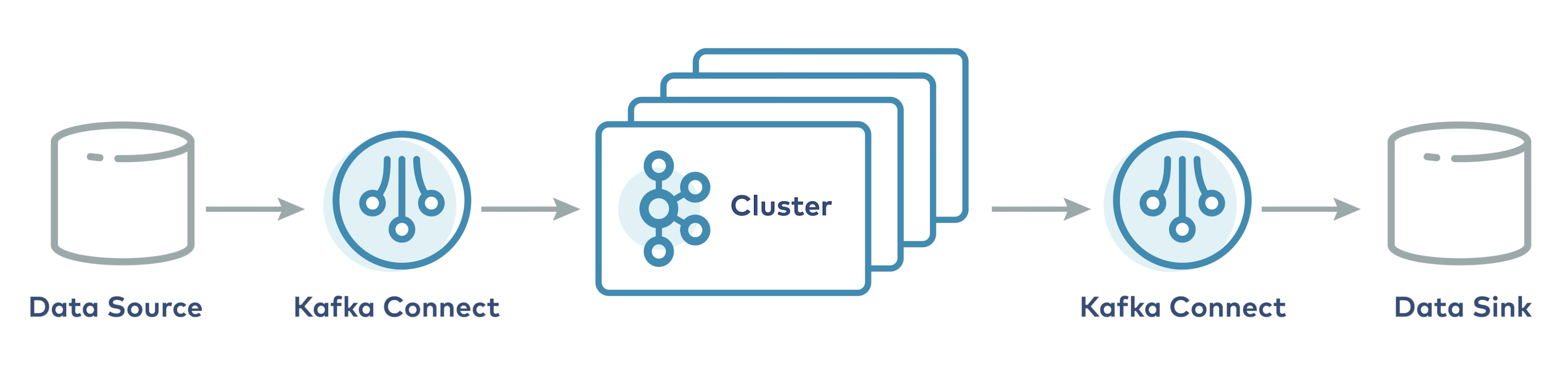
- Connect worker runs one or more connectors
- Connectors
- pluggable software component
- interfacing with the external system
- Also exist as runtime entities
- Source connector (acts as Producer)
- reads data from and external system and produces it to a Kafka topi
- Sink connector (acts as Consumer)
- subscribes to one or more Kafka topics and writes the messages it reads to an external system
Benefits of Kafka Connect
- large ecosystem of connectors
14. Confluent Schema Registry
- To solve two problems
- New consumers of existing topics will emerge
- → need to understand the format of the message in the topic
- The format of those message will evolve as the business evolves
- → the schemas of domain objects is a constantly moving target
- must have a way of agreeing on the schema of messages in any given topic
- New consumers of existing topics will emerge
What is Schema Registry
- Sever Process external to Kafka brokers
- Job: maintain a database of schemas
- schema: that have been written into topics in the cluster for which it is responsible.
- database: internal Kafka topic and cached in Schema Registry for lower latency access
- Consumer/Producer API Component
- Process
- calls on API at the Schema Registry REST endpoint
- presents the schema of the new message
- Response
- Produce side
- if same as last message → produce succeed
- if different from last message
- but matches the compatibility rules defined for the topic → produce succeed
- violates compatibility rules → produce fail in a way that the application code can detect
- Consume side
- Consumer API prevents incompatible message from being consumed
- Produce side
- Process
- Support Formats
- JSON Schema
- Avro
- Protocol Buffers
16. Kafka Stream
- Consumer tend to grow in complexity
- started from stateless transformation (masking, changing format)
- →being complexity → stateful
- state
- memory allocated in program’s heap
- → fault-tolerant liability
Kafka Stream
- Functional Java API
- Filtering, grouping, aggregating, joining, and more
- Scalable, fault-tolerant state management
- Integrates within your services as a library
- Runs in the context of your application
- Does not require special infrastructure